4 Philosophies For Building Systems To Be Proud Of
Below are a few philosophical guidelines that I use when thinking about systems. Everyone has systems that they are not proud of, even me. But I hope to someday say that I am proud of all of my systems, and I believe that these philosophies will get me there.
1. Try to endeavor to build systems with as few dependencies as possible.
Sometimes systems can sprawl and get out of hand. Before you know if you have all your servers using ldap, which gets looked up by DNS, and the DNS server has a mysql backend, which is stored on an NFS mount. So… what happens after a power outage and your servers boot from scratch?
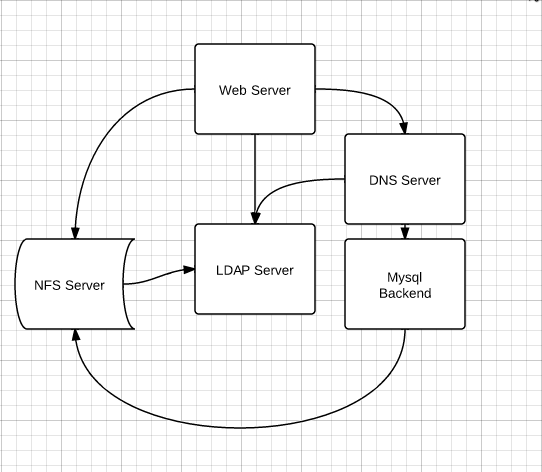
The above example seems obviously broken, but sometimes it is not so obvious with our own systems. (Nobody builds stuff like that… right? :)) Our own familiarity with our own systems can blind us to their internal fragility. Some tips on how to achieve this:
-
Use /etc/hosts instead of DNS for critical servers (don’t go crazy here). CFEngine can do this easily for you.
-
Use LDAP sparingly, and configure it to allow root to login when the LDAP server is down. Run a test with the ldap server off to confirm that your servers can function at all. (Login, reboot, startup, etc)
-
Don’t use network filesystems (samba, nfs, sshfs, etc) when simple rsyncs would do. Mountpoints suck. Keep it local if possible.
-
In smaller systems, try to keep database, application, and web servers on the same server. I know how it sounds, but sometimes everything you read in CIO Magazine isn’t what works best for all environments. Sprawling connected services over multiple servers makes the system as a whole less reliable, not more reliable. (Unless you are doing HA specific stuff)
2. If there is a problem with your system and your monitoring system didn’t alert you, you have two problems.
The second problem, of course, is that your monitoring system isn’t monitoring. Sure it may be checking pings or seeing if TCP port 80 is open. Can it detect when the website has a database connection failure? Will it send you a text when visitors can’t add things to the shopping cart? Does it go red when the credit card api is failing?
Most of the time when responding to an urgent problem, the last thing on a sysadmin’s mind is writing a nagios plugin. But I suggest it should be the first. If it isn’t urgent, include the act of writing the nagios check part of the problem solving process. Use an all green nagios (and a manual verification) to be the final signal for the all-clear. A nagios check is never fully tested unless it shows red under a truly failed condition. Sure, you could write the nagios check later, but you can’t be 100% sure it will turn red next time, it might take a couple tries. Turn the failure into an opportunity.
3. With bigger systems, try to design them so that no single server reboot stops the whole system.
This is a reformulation of the first philosophy, really. All servers need a reboot some day. Be proud of a system were you can reboot any server without asking for permission with minimal impact to your services. This is not achievable in all environments, but it sure is something to be proud of if you can make it happen.
4. Systems should be self documenting
This is a controversial topic. There are some in a particular camp that believe that “Documentation” means some three ring binder with chapters describing each server, install walkthroughs (with screenshots), and copies of the apache configs on paper. I am not of that camp…
I believe the system itself should be self-documenting. What do I mean by this? Take the simple issue of hostnames as an example. Some like to give servers cutesy names based off of Nintendo characters, dog breeds, obscure hacker culture references, etc. These names may be good for some sort of security through obscurity, but they do not encourage a self documenting system. Hostnames like ldap1, ldap2 or mysql, or webserver make it easy for humans to develop models in our heads for how our systems work on a grand scale.
How about another example: switchport configurations in managed switches. For some switches it is important to know what server is on what port. (vlans, poe, qos, etc) Should we print out our “show run” in order to be the documentation? I suggest we do not. It will be out of date the instant it was on the dead-tree medium. The only case one could make for having that kind of copy would be for a backup scenario. To that I would ask, “are you not making backups of your switch configurations already?” No, the switch configuration of a switch itself is the documentation for the switch. There is no need to maintain records of switch configurations in two places.
Another powerful example of a self-documenting system is the power of CFEngine. Remember that hypothetical three ring binder that has the description of how to setup each system in your server room? Yea, the one that is forever out of date and is useless to anyone except for the reason to say that you have “documentation?” Your CFEngine configs are the living digital version of that three ring binder. CFEngine itself can contain all the recipes, ingredients, workflows, and special sauce to recreate your systems. Need a copy of your documentation? It’s /var/cfengine. It is mostly human readable anyway. Print if management requires it, but the digital copy is your golden copy, not the paper.
For everything else, I keep a wiki. It works for me.
Comment via email