Discrete Wavelets Final Project - Decaptcha,
This semester I took a class on Discrete Wavelets. It was awesome. The coolest part was our group final project. My group had the best topic by far: Decoding a Captcha! (Click on any of the following images to view them full size)

{kind=link}
We’ve all seen Captchas before. They are used on websites to make sure that the person on the website is a real human, not a computer program. Why do we want to break them? The same reason we want to climb Mount Everest, it’s There!
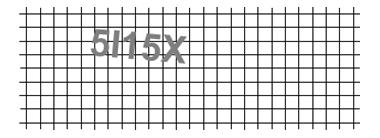
The above is the captcha we intended to solve. Its not particularly difficult, but this class is an introduction to wavelets and requires no previous experience with the language we had to use: Mathematica. Our real task was to implement the algorithm in this paper.
So how do we do it? First we need to isolate the image without the background.

No problem. The color of the text is different from the background so it is easy to isolate. Next we need to take those pieces of the matrix and turn them into a list of coordinate pairs. Then we can apply a rotation matrix transform to undo the angle. What angle? Well I don’t know. How can we figure out how much it was rotate? Of course! Linear regression from Statistics!
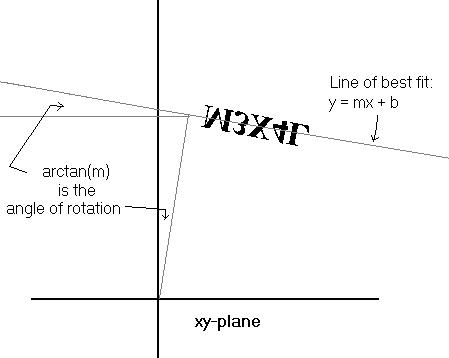
Fortunately Mathematica has a function for this. This is the easy part. Now we need to take these rotated vectors and “Unrotate” them, then put them back into a matrix:
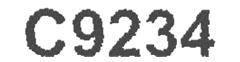
No problem! Well actually this isn’t as easy as it sounds. Arbitrary image rotation is non trivial. But let us press on. Now we must Cut the image into its component letters. This is easy, the columns of the matrix that are all white are the demarcation points.
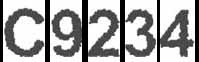
Ok now what? Well we have an individual matrix for each unknown letter. Let us resize it to a standard square size (pad it), say 80x80. Oh I forgot to mention, before we stared on this we made a “Canon” of letters from A-Z0-9 with the same font into 80x80 squares too. At this point we could compare each letters “difference” and see which has the least difference. Let me show you:

Eh so that is a crappy example. When you take two letters and subtract them, you get all black where they are the same, and some white or gray where the “differences” are (Math terms=2 dimensional norm). The letter with the least difference is most likely to be the original letter.
So all we have to do is iterate through each canonical letter until we get the least difference. Do that for each letter and we can decode (you can see the unknown on the left, and the matching canon on the right):

Seems pretty good. But it gets better with some Discrete Wavelet Magic! Our comparison can get even better if we ignore the errors and wavey crap that was introduced in the align section. The way we do this is with the Haar Wavelet Transform. Don’t mind the math, we are basically blurring the image:
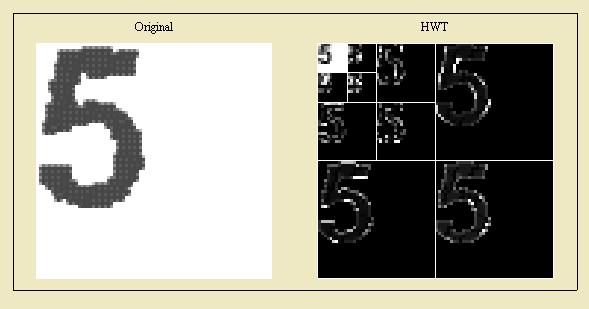
The part we want is in the upper most left hand corner, the “blur”. It turns out that 3 iterations of the HWT gives the best results. By doing this we were able to decode our CAPTCHAs 75% of the time. In the end the major flaws take place in the linear regression and the align function. If we used Mathematica 7 instead of 6 we could have used its built in image processing functions to take the error out of our sloppy rounding.
But of course, the proof is in the code, I mean, the pudding. Here is our notebook:
Mathematica Notebook To use this you need the Discrete Wavelets Package. Mathematica 7 comes with a function but this is written for 6.
Notebook for Mathematica Player Not everyone has Mathematica, but their player is cross platform and free as in beer.
Our Powerpoint Presentation Blarg… If someone can convert this to pdf I will change this.
Comment via email